
Sitting in the systems of every lender is an enormous volume of untouched signals: the plain-text fields in loan applications, the customer communications, the narrative credit memos, the call notes, the click data, etc.. A credit officer can recognize these signals on any single application. What no lender could do was surface these signals systematically across an entire loan book at decision speed. Models, until recently, could not do this at scale.
The economics of closing this gap are significant. For a large consumer lender, even a single basis point improvement in charge-off prediction or mitigation translates into millions in annual P&L impact across the book. A model that can separate an additional tranche of bad loans from good ones — or confidently approve loans that a blunter model would have declined — compounds directly into origination volume, loss reduction, and capital efficiency.
We know that today’s large language models can read a piece of unstructured text and “understand” it at a semantic level. That much is obvious from the performance of today’s AI chatbots. However, LLM context windows are usually capped at around 1M tokens (and their useful size is often closer to 200K tokens); you physically cannot fit a “big data” corpus into a prompt and ask what patterns predict default. The real question for risk leaders is not whether to use LLMs on unstructured data, but which methodology you adopt to surface patterns from it.
The standard workaround: Topic clustering
The current industry workaround, often called topic clustering, groups similar pieces of text together and then uses a flagship LLM to label each group with a human-readable theme.
This is genuinely useful. It sidesteps the context-window problem and produces readable, executive-friendly themes. For broad voice-of-customer work, complaint analytics, or marketing exploration, it is often enough. For credit decisioning, however, it falls short on the things that matter most:
The long tail disappears. A rare-but-predictive pattern, such as language signaling a small-business owner about to overextend, or an early indicator of elder fraud, gets absorbed into a larger nearby cluster and never surfaces as its own signal. The long tail is precisely where credit risk lives.
Patterns cannot compose. A loan narrative from an applicant starting a new business, with mounting credit-card debt, written in an emotionally urgent tone, is dumped into one bucket. The intersection of those three risk signals, which is often where the real prediction lies, becomes invisible.
Results are not reproducible. Re-run the pipeline with slightly different parameters and you get different clusters, with different names and different boundaries. For longitudinal monitoring, this is a serious limitation.
Themes can be hallucinated. Flagship LLMs sometimes invent plausible-sounding themes that are not actually in the data. The output looks authoritative on a slide, but the underlying signal may not exist.
A better way: mechanistic interpretability with SAEs
A more rigorous approach is to look directly inside the LLM at the features it actually uses when processing text. This is the domain of mechanistic interpretability, and its workhorse technique is the sparse autoencoder, or SAE. Rather than asking an LLM to summarize what it sees in clusters, the SAE approach decomposes the LLM’s internal representation into a fixed, interpretable feature dictionary. Each piece of text activates a small subset of features, and each feature corresponds to one specific concept, such as “discretionary home improvement language,” “emotional urgency in all caps,” or “small-business formation context.”
For credit risk specifically, this matters in concrete ways. Rare-but-predictive signals get their own dedicated features rather than being averaged away inside a cluster. The same input produces the same features every time, which gives you reproducibility for audit and a stable foundation for monitoring drift in unstructured signals over time. And because features are mathematically derived from the model’s actual computation, you can show a credit officer or regulator exactly which signal influenced a decision, rather than a post-hoc explanation generated by the model after the fact.
To show what this looks like in practice, we applied this approach to a real credit risk dataset.
Proof of Concept: Lending Club Loan Descriptions
To demonstrate what becomes possible, we applied mechanistic interpretability to a real credit risk dataset: Lending Club’s peer-to-peer lending portfolio of approved high-risk customers from 2008-2014, which includes a free-text field where loan applicants describe the purpose of their consumer loan.1
We processed the user-provided loan descriptions through a large language model and used sparse autoencoders (“SAEs”) — a core technique from mechanistic interpretability — to decompose the model’s internal activations into interpretable features.
We trained SAEs with 40960 features to decode activations from layers 10 and 14 of Qwen 3-1.7B. Importantly, the training data for these SAEs included the collected loan descriptions as well as additional consumer personal finance content. This encouraged the SAEs to learn concepts and patterns that are prominent in the loan descriptions data, and which would likely be relevant for the charge-off prediction task. Once trained, extracting feature activations from the full corpus of approximately 100,000 loan descriptions takes only a few minutes, and later analysis uses standard statistical and machine learning methods.
Features our SAEs found in the LLM’s processing
Among the most influential features the SAE identified in the LLM’s processing mechanisms were the following (note that text is verbatim from the original applications):
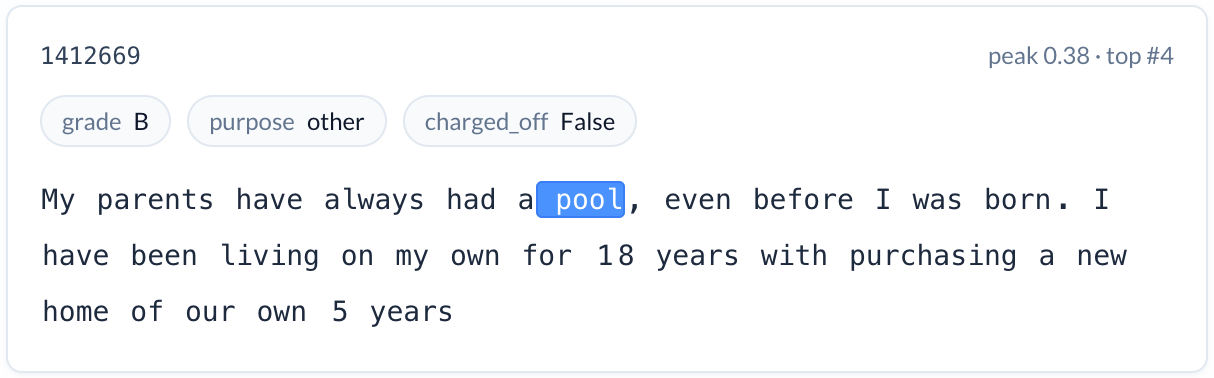
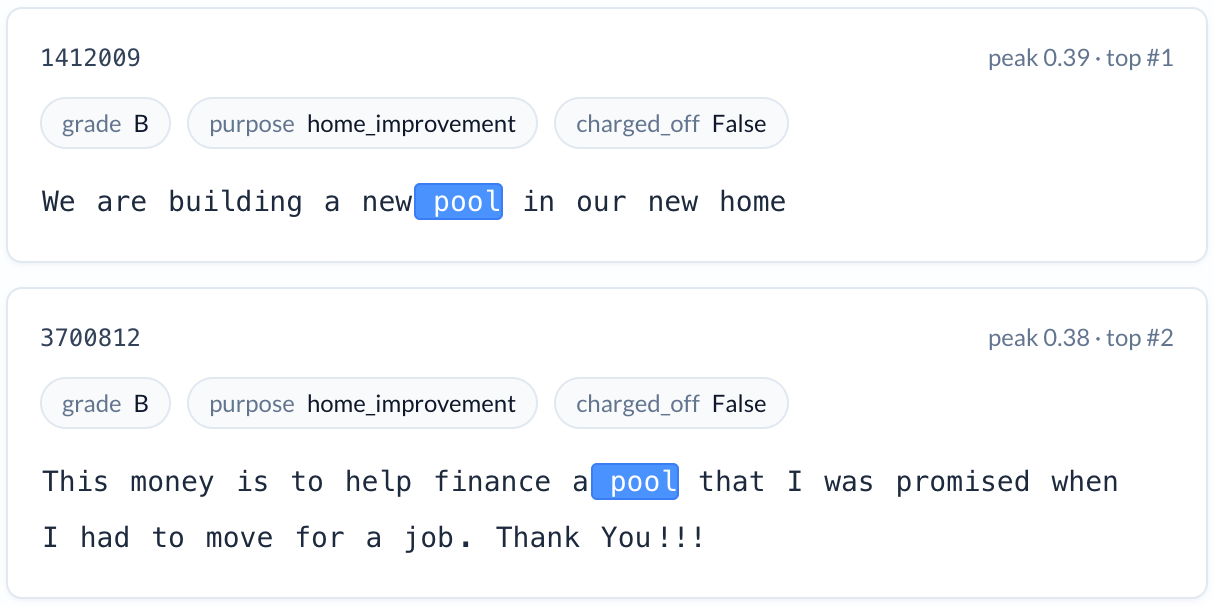
Discretionary home improvement (reduces risk). A feature that activates on discussions of building swimming pools — a specific, discretionary purchase indicating financial stability and homeownership. Loans with this feature active had a charge-off rate nearly 10 percentage points below the baseline, even relative to the already-lower rate for home improvement loans generally. We might see this as correcting for a common spurious pattern in traditional credit scores: expenditures on a large home improvement can raise credit utilization rates and temporarily lower credit scores without any real change in consumer propensity to repay.
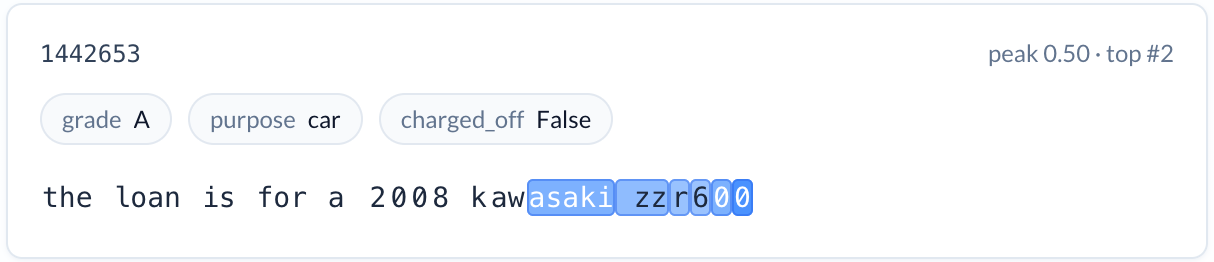
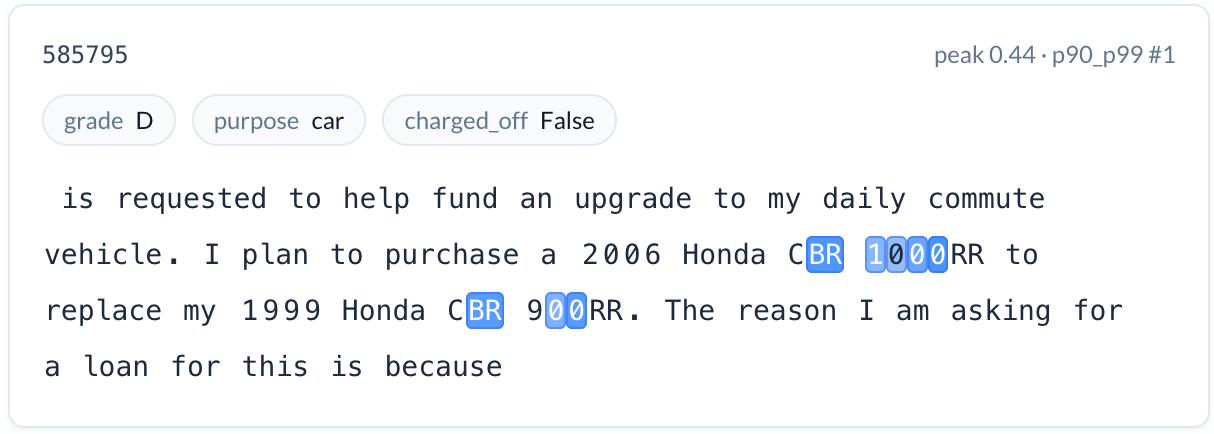
Specific vehicle purchases (reduces risk). A feature activating on motorcycle model names and specifications — applicants describing a 2008 Kawasaki ZZR600 or a 2004 Harley Davidson Sportster XL1200R. The charge-off rate is 7.3% versus the 15.2% baseline. These are applicants who know exactly what they want and have researched the specific asset they’re purchasing. Note that the term “motorcycle” is often not used at all, so the power of a foundation model is needed to extract the semantic meaning.
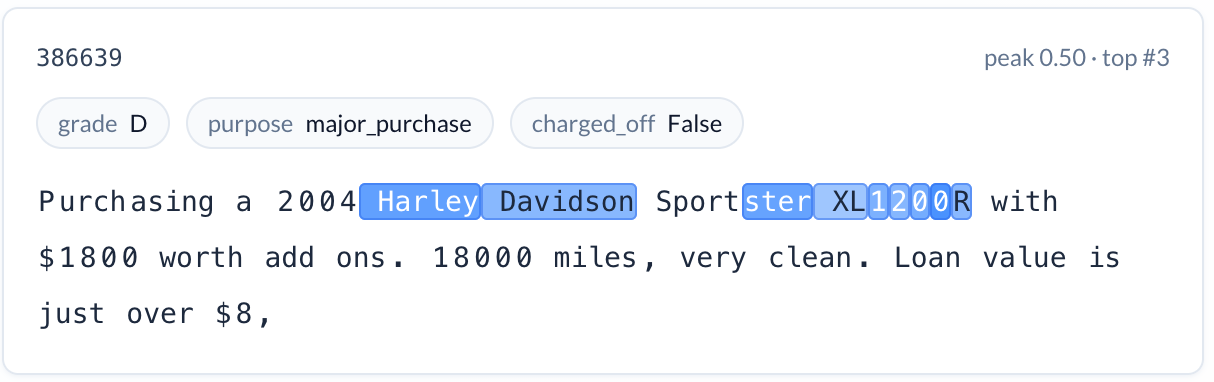
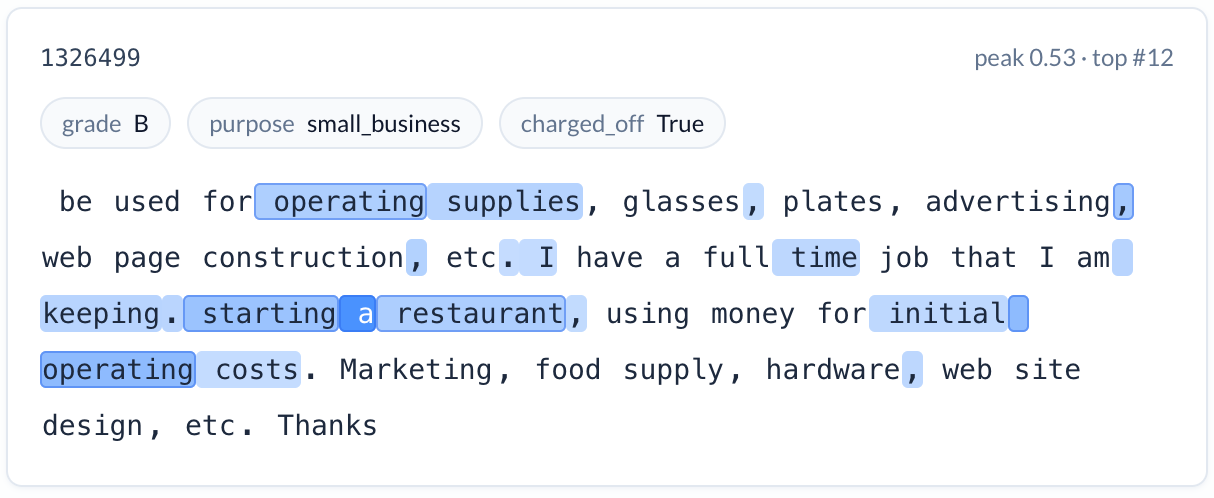
Business formation language (increases risk). A feature activating on descriptions of starting or opening a business — restaurants, salon studios, new ventures. Charge-off rate: 23.5%. Starting a small business is inherently risky, and the model correctly identified this signal from the narrative.


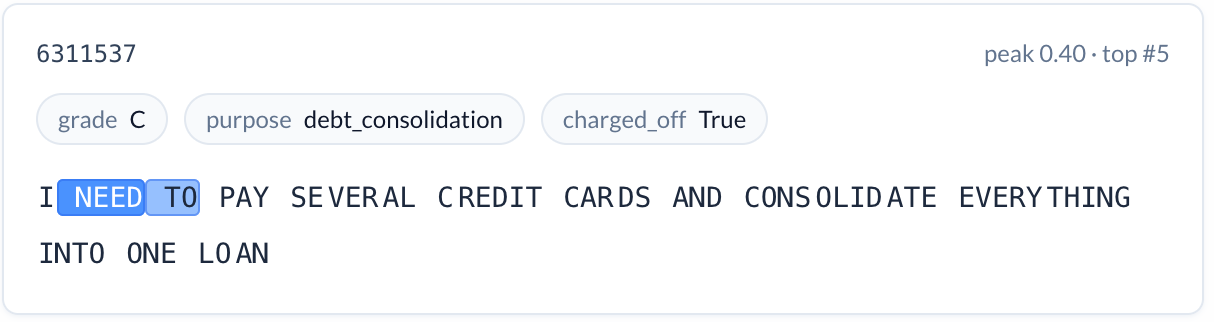
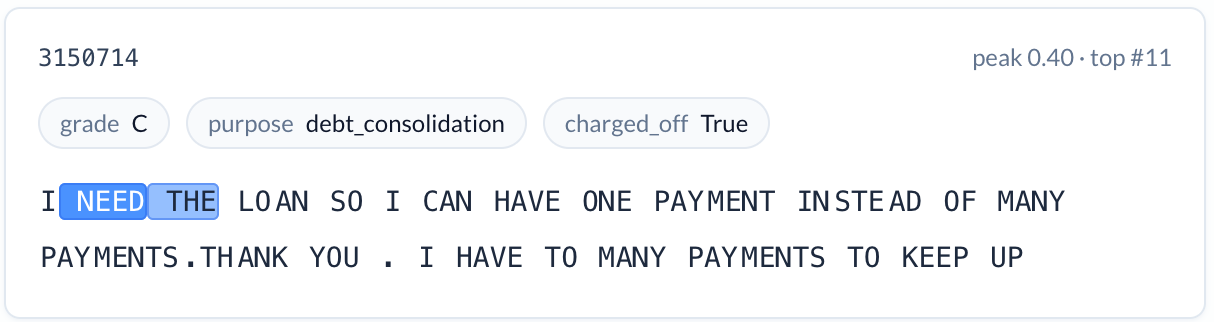
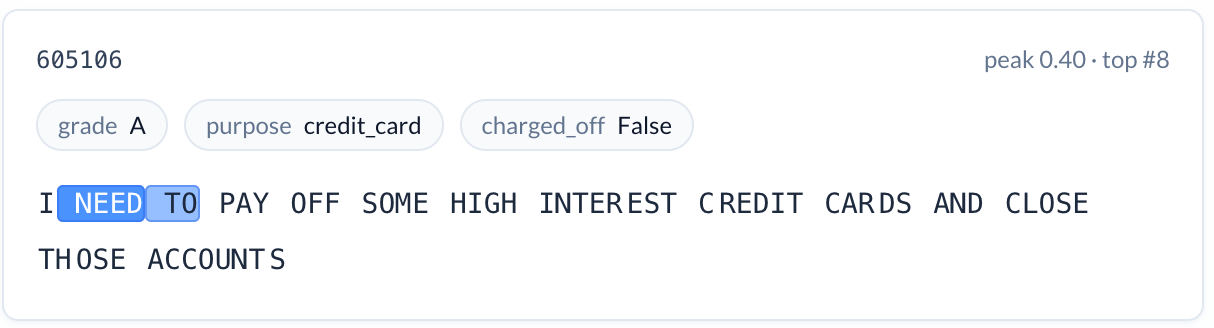
Emotional urgency (increases risk). A feature activating on strong statements of need, especially in all capitals. “I NEED TO PAY OFF SOME HIGH INTEREST CREDIT CARDS.” Charge-off rate: 19.0%. The desperation conveyed through language and formatting is a signal that structured data cannot capture.
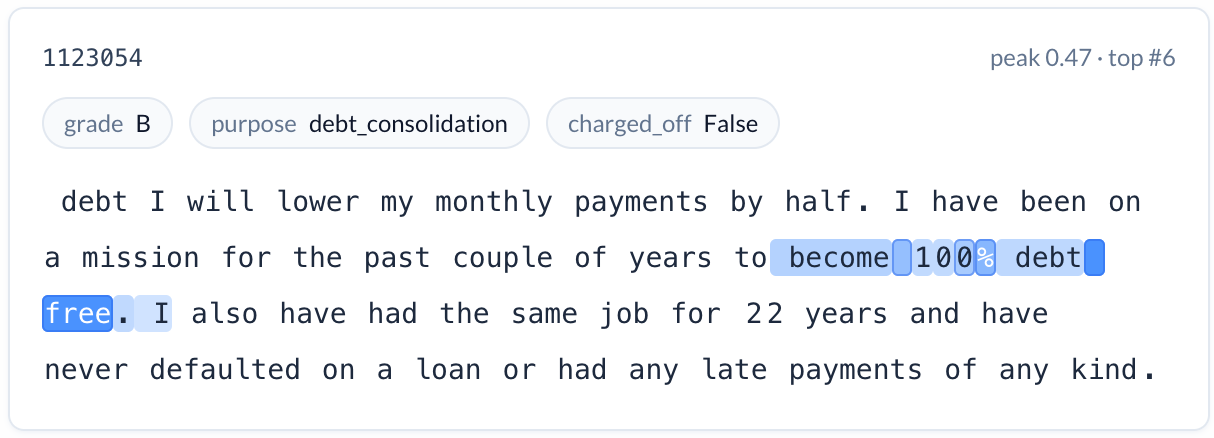
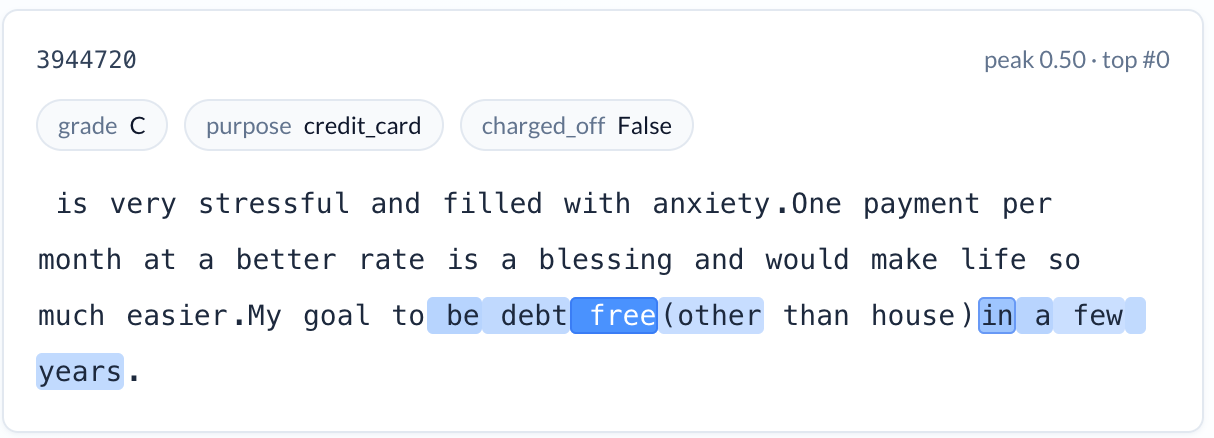
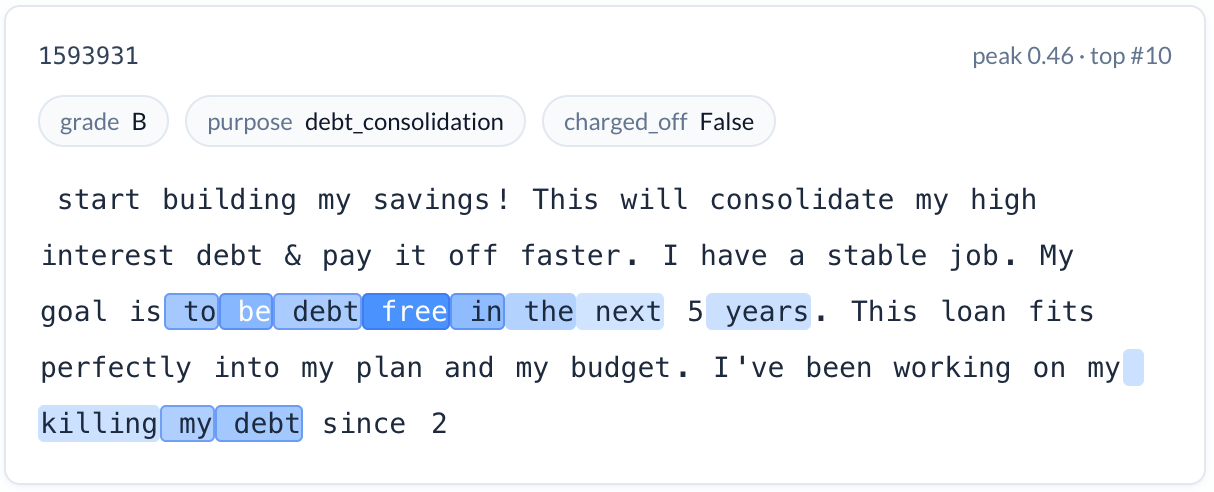
Financial planning language (reduces risk). A feature activating on articulated plans to become debt-free — applicants who describe a concrete goal, a timeline, and a strategy. Charge-off rate: 12.6%. An applicant who writes “my goal is to be debt free in the next 5 years — this loan fits perfectly into my plan and my budget” is telling you something about their relationship with debt that no credit score captures.
Grammatical errors and typos (increases risk). A feature activating on misspellings and malformed text — “credir card,” “paymenat,” “currentlty.” Charge-off rate: 19.9%. This may reflect attention to detail, care in communication, or educational background — all of which correlate with credit behavior in ways that structured fields cannot express.
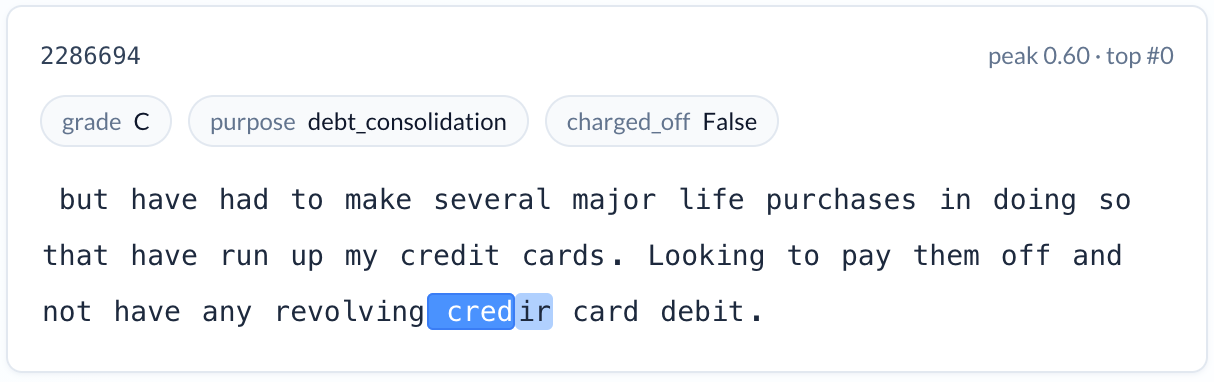
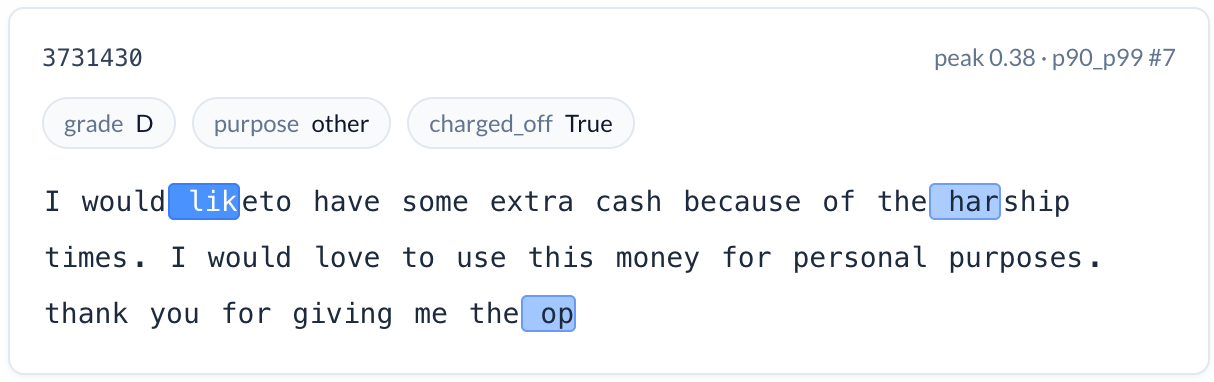
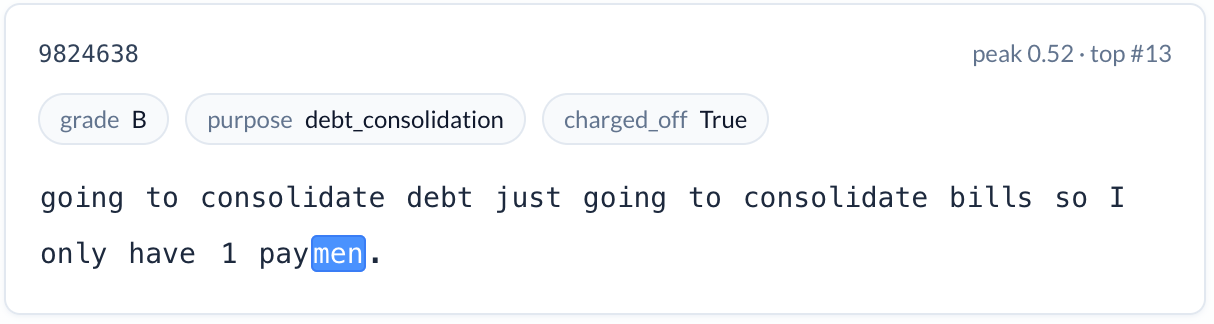
None of these signals are available in traditional credit bureau data. All of them are intuitive to a credit professional. And every one of them was discovered by examining which interpretable features activated inside the LLM’s internal representations — not by asking the model to make up an explanation about its output.
This is what risk-based validation looks like. A credit officer reviewing a decline or approval can see exactly which signals from the applicant’s own words influenced the assessment. They can effectively challenge the attribution: is the swimming pool feature really about financial stability, or is it a proxy for zip code and therefore race? They can test it: does the feature activate on other discretionary home improvement language, or only on pools? They can make an informed judgment about whether to follow or override the model’s signal. The explanation indicates conceptual soundness because it’s grounded in the model’s actual computation, not fabricated after the fact.
Proof of Concept: Are these features predictive?
We combined the above features with the platform’s existing loan grades in a sparse logistic regression predicting loan charge-off. (We considered using additional tabular features from the dataset, but initial experiments showed they provided extremely limited uplift over the loan grade, and so we used the loan grade as a convenient distillation of the standard underwriting process.)
We used the SAEs to extract per-token feature vectors from each loan description, and aggregated features across tokens in a description by taking the maximum activation value per feature, dropping very rare and very common features. We then trained an L1-regularized logistic regression using the one-hot-encoded loan grade along with the aggregated features, predicting the probability of loan charge-off. The resulting model used fewer than 200 SAE features. As a comparative baseline, we also extracted classical TF-IDF features from the loan descriptions; these features indicate the presence of specific words in the text rather than higher-level concepts.
Adding the SAE features to the loan grade yielded a small but significant increase in average precision of the classifier. This difference of ~0.02 means that, averaged across all possible risk score thresholds, the applications flagged as high risk by the new model are about 2 percentage points more likely to result in charge-off than the grade-only predictions.
Complete results are in this table:
| Model | Average Precision | AUC-ROC |
|---|---|---|
| Loan grade only | 0.239 | 0.669 |
| SAE features only | 0.193 | 0.586 |
| TF-IDF features only | 0.189 | 0.574 |
| Loan grade + SAE features | 0.263 | 0.679 |
| Loan grade + TF-IDF | 0.242 | 0.653 |
The SAE and TF-IDF features are able to capture meaningful information about risk even without any access to traditional signals like credit scores, income levels, or loan amounts, with the SAE features performing better than the TF-IDF features.
The predictive uplift from the SAE features is a clear sign that there is useful information in the loan descriptions that is currently going unused. That information could be used to extend the risk score model, but could also be used in other ways. For instance, knowing that pool builders or motorcycle buyers with a clear purpose are lower risk might better inform marketing efforts.
Where This Goes Next
The Lending Club analysis is a proof of concept on predicting credit risk from model internals. However, such validated, interpretable features from LLM processing are re-usable across a wide range of credit decisioning applications.
Consumer credit narratives. Many lending platforms and credit applications include free-text fields. The signals we found in Lending Club descriptions are a sample of a much richer feature space available wherever applicants describe their circumstances, intentions, and financial context in their own words.
Business credit memos. In commercial lending, the credit analyst’s narrative memo documents the qualitative case supporting a credit decision. These memos contain judgment, context, and risk signals that don’t fit into structured fields. Mechanistic interpretability can extract consistent, auditable features from these narratives — turning qualitative analyst judgment into quantitative, validated risk signals without losing the interpretability.
Customer interaction signals. Call transcripts, chat logs, email correspondence, and complaint records contain latent risk signals. Changes in customer communication patterns — tone, urgency, topic — can indicate evolving credit risk before it appears in structured performance data.
Semantic guardrails. Beyond feature extraction, the same techniques can implement content-based controls on unstructured inputs — automated referral triggers when specific topics appear in credit narratives (e.g., litigation, regulatory action, related-party transactions), without relying on brittle keyword matching.
Ongoing monitoring. Feature activations can be tracked over time across decision populations, providing an early warning system for drift in unstructured content signals. If new features start appearing in high-risk decisions that weren’t present during development, that’s a signal for a deeper review of the underlying data or the model — long before aggregate performance metrics would detect the change.
Escalation and special handling. Mechanistic interpretability features can flag unstructured content that indicates the need for specialist review: application fraud indicators, signs of insider fraud, tax residency indicia under the Common Reporting Standard, or other regulatory triggers that are embedded in narrative text rather than structured fields.
Decision agents within agentic systems. Complex agentic workflows can delegate key decisions to specialist explainable agents, unlocking agentic use-cases that need to make impactful decisions as part of the processing flow.
The Opportunity Ahead
We are entering a period where the barriers that kept unstructured data out of credit decisioning systems are falling. LLMs can process the text. Banks, lenders, and insurers will all put AI to work on their unstructured data. What separates them is the method they pick, and whether the signals it produces are reliable enough to bet money on.
For credit decisioning, underwriting, and risk monitoring, the SAE-based approach is the right answer. It surfaces the long tail of risk where charge-offs live, exposes the compositional patterns where multiple weak signals combine into one strong one, and grounds every explanation in the model’s actual computation. The result is a signal that is sharp, reproducible, and defensible to regulators by construction.
The power of combining language models methodically with statistical models, using interpretable features extracted from inside the LLM as inputs to a sparse, validated risk model, is the new frontier in credit risk prediction. In a market where marginal improvements in model lift have material financial consequences, this combination is more than a technical preference. It becomes a durable competitive advantage: improved understanding yields positive selection for the lenders and insurers who adopt it, and adverse selection for those who do not.
The barriers that kept unstructured data out of credit decisioning systems are falling. LLMs can read the text. Mechanistic interpretability can make the reading transparent, reproducible, and defensible. The institutions that move first will have a meaningful edge, not just in model accuracy, but in their ability to make credit decisions that are simultaneously sharper, more transparent, and more defensible.
BluelightAI is one of a small number of AI labs with the research capability and industry relationships to bring mechanistic interpretability from frontier AI research into production financial services. Our team combines pioneering expertise in Topological Data Analysis and Mechanistic Interpretability with deep experience in banking, financial services, and insurance.
To discuss how these techniques can enhance your credit decisioning systems, contact support@bluelightai.com.
Footnotes
-
This dataset is one of the most realistic freely-available datasets for credit prediction tasks, but does have significant differences from typical consumer lending cohorts, most notably the high charge-off rate of around 15%. This is likely a selection effect from a new platform attracting customers who had difficulty obtaining credit elsewhere or had other reasons for avoiding the traditional banking system. Another shortcoming of the data is that full customer profiles (including loan descriptions) are only available for loans that were actually made; there is very little data on rejected applicants, and our analysis uses only data from loans that were actually booked. ↩